Hi, I am Rob Ellis, Senior Data Engineer at Essex County Fire and Rescue Service (ECFRS), and in this blog we will start to explore our journey migrating to Microsoft Fabric, the good and the areas that perhaps need some polish.
In ECFRS, we have a goal of having a centralised data platform to feed all our downstream analytics and data needs. We recognise the importance of having a data platform that provides robust and accurate data for the service, allowing for strategic and tactical decision making.
So, what is Microsoft Fabric? Fabric is an end-to-end, cloud-based SaaS (Software as a Service) analytics solution, covering everything in the “analytics workflow”, from data ingestion, warehousing, visualisation and data science.

How did we decide on Fabric? In mid-2023, we were exploring Azure Synapse Analytics, and somewhat surprisingly Microsoft announced Fabric, which threw a spanner in the works! We elected to pursue an F64 Fabric capacity [a Fabric capacity that dictates how much compute (or oomph!) the capacity has available. Expressed as compute units, in this case 64] for some of the reasons listed below:
- We felt in the long run Fabric should work out more cost effective, especially as F64+ includes Power BI Premium
- Fabric is the leading analytics solution from Microsoft and is being improved frequently, whereas Synapse developments have stagnated
- Easier to admin and integrate, as it is a more “managed” service
- A more streamlined data engineering and data science experience (arguably!)
There are of course risks in being an early adopter, however we felt the benefits outweighed the risks and matched our organisational goals and aspirations.
Our chosen architecture is summarised in the visual below. Like Synapse, Fabric provides a lot of flexibility in how you can achieve things, which is a blessing and a curse. I have certainly found, being new to the “modern data stack” and its various technologies, that it can be quite daunting to know what the “best” approach is.
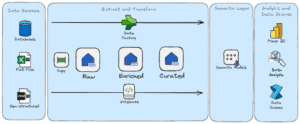
I won’t go into much technical detail in this post (unless you’d like me to? Leave comments on the blog and I can do a future blog if there is an appetite for it. I can talk about this stuff for hours, as my colleagues will attest…), but to summarise our current structure:
- Copy data from sources (databases, APIs, Excel and CSV files etc) using metadata driven pipelines
- Progressively transform and enrich data through a medallion style architecture [a way to organise data in a data Lakehouse by separating it into different "layers" based on its quality and readiness for analysis] (raw, enriched and curated Lakehouse’s), mostly using Spark SQL (and a touch of PySpark) notebooks
- Centrally managed semantic models [a way to represent information that focuses on the meaning and relationships between concepts rather than just the raw data], themed around key areas of the service (Operations, HR and Finance etc), to feed most Power BI reporting
- These steps are orchestrated by Fabric Data Factory
- Data can be queried in many ways, including T-SQL via the SQL endpoint, Spark (which supports languages SQL, PySpark, R and Scala), and via our most used tools, such as Power BI and Excel
The above generally works well, however it isn’t all sunshine and roses. Some of the pain points we currently have:
- Git version control integration, in our experience, is buggy and slow
- Data management and governance features are a bit lacking
- Continuous integration/continuous deployment/development (CI/CD), whilst technically doable, isn’t as streamlined and doesn’t offer as much automation as it probably should
The above makes following the software development lifecycle and best principles challenging, however some of the above is on Microsoft’s roadmap for improvement, and we are working with them to try and resolves our issues.
I hope this post, albeit brief, highlights what we are doing in ECFRS in the data engineering space, the adopted tooling and architecture, and some of the pros and cons of Fabric. Like many of our partner organisations in Essex, we are still very much early in our migration journey and have a lot more to do. However, I believe we are moving in the right direction of providing a modern, robust and future proof data platform.
Having the support of a Data Engineering community of practice, facilitated by the Essex Centre for Data Analytics (ecda), has provided an opportunity to meet regularly with my counterparts from across public sector organisations in the county. Communities such as these provide the equivalent of a professional hive mind when you’re embarking on transformational data programmes; like minded colleagues adding value by sharing knowledge, and importantly filling knowledge gaps, breaking down the complex into practical and achievable steps, stretching thinking to promote innovation, and hopefully providing a blueprint for the next partner to build upon.